Manage and Optimize BigQuery Analysis
BigQuery is a flagship Google Cloud product. It is a managed data warehouse service. Its integration into Google and 3rd party ecosystems makes it a powerful tool for democratizing data. It can become one of your largest Google Cloud Platform (GCP) costs - and brings unique management challenges.
As your BigQuery use increases it is important to get better at managing its cost. The practices covered in this article can ensure you’re getting the greatest value from your BigQuery investment.
This article addresses the management challenges of running BigQuery on a large scale. The practices in this article provide visibility into the who, what, and why behind your analysis costs. They will help you improve the performance and reduce the cost of your queries.
The focus of this article is Analysis costs, which is specific to query activity. You may have other BigQuery charges such as Active Storage, or Storage API costs. Those other costs are not the scope of this article.
You can find many technical articles detailing how to optimize BigQuery queries through specific techniques. We won’t seek to provide a better explanation of those techniques. We will provide an overview of the practices, and then link you to further reading on the techniques.
BigQuery Pricing Model Overview
It is important to understand BigQuery’s unique pricing model as you seek to manage its cost.
BigQuery uses a concept of a Slot1, which can be thought of as a “Virtual CPU”. It is a unit of a resource that will be applied to processing your query.
There are two models for paying for BigQuery analysis: Pay-Per-Use and Reserved Slots.
Under the default Pay-Per-Use cost model you are billed per TB of data processed by your queries. Under this model, Slots are dynamically allocated - up to 2000, by default - to provide a response. Slot limits can be increased to allow you to spend money faster, or BigQuery may burst beyond 2000 to accelerate queries2.
With Reserved Slots3, you have a fixed capacity of slots that you pay for regardless of how much you use it. You are not billed based on the amount of data processed by your query, however, the performance of your query (and all other queries under the scope of the same reservation) will be constrained by your slot reservation.
The practices listed below are helpful under either model. The primary factor for cost (and performance) under both models is the amount of data processed, which is the primary consideration for how many slots are needed to provide adequate query performance.
Cost Management Practices
We’ve organized practices by role (or hat) of the person who would typically implement them. You’re encouraged to cherry-pick and use the practices that will have the maximum impact and greatest value for your organization. If you’re an individual consumer of BigQuery data, as opposed to someone responsible for managing the BigQuery use in across a team or organization, feel free to jump to that section. Many of these practices will, in practice, will blur lines and require collaboration between the different roles. As always when approaching GCP cost management, collaboration is essential.
Quick-links to practices for the following roles:
Platform Manager
A Platform Manager is one who handles an organization’s overall use of GCP and/or BigQuery. They probably have the Billing Admin role, and broad project visibility.
The following practices are around providing overall visibility into BigQuery usage. Who is using it, and what are they using it for? It is focused on giving organization leadership the information they need to understand the BigQuery expense, and its specific value provided to the company. It is also focused on giving visibility to the consumers on their spend so that they can use that information to self-optimize.
Audit all queries via Stackdriver Log Sink
You may track the detailed usage of BigQuery by creating a Log Sink to record metadata for each query executed. The log sink writes the metadata to a BigQuery table, and the data can provide insights to support many of the practices in this article. This must be configured for every GCP project where BigQuery queries are being executed. An example of this is provided in Step #1 of Google’s BigQuery Pricing CodeLab4.
Break Down and Attribute Job/Query Costs
Logging all queries is helpful, but to gain the most insight you need to separate your query costs so that you can associate costs to a particular person or service, or the value provided. You can break down your costs using the following mechanisms:
- Project: The project where you execute your BigQuery query job is independent of the project where the dataset(s) you may be querying reside. This means, if your datasets are located in ProjectA, the query job can be executed in ProjectB to be associated with that project (and its billing account).
- User: The user executing the BigQuery query. This might be an individual employee or a Service Account.
- Label: further breakdown as appropriate for your business. e.g., a
customer-idlabel can help you track BigQuery work for a specific customer.
Create BigQuery Consumption Dashboard
Providing a friendly view of your query costs is a big step toward cost management and optimization. With visibility into usage, teams that are using BigQuery can understand what they’re spending, and what queries are costing the most or consuming the most resources. Google’s free Data Studio5 can provide a simple reporting interface based on the BigQuery table generated in the query audit detail.
An example DataStudio dashboard is available on Step #4 of Google’s BigQuery Pricing CodeLab4.
This information can be reported on and teams can receive regular reporting on their consumption.
Highlight Most Costly Queries
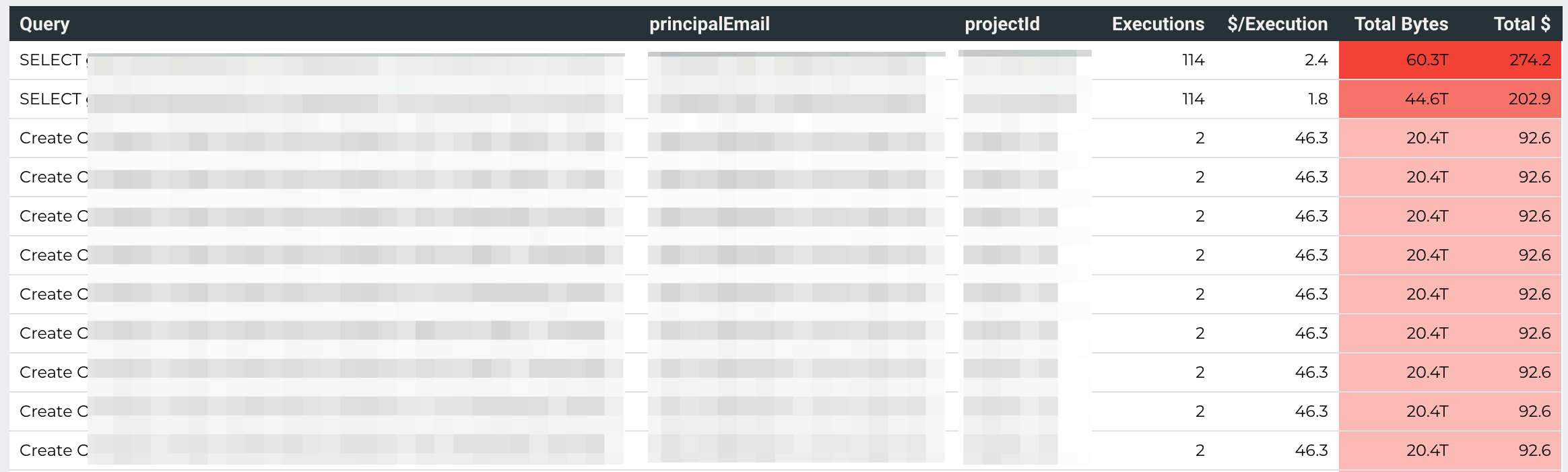
Generate a “Weekly Most Expensive Queries” report from this audit data, and include detail on the most costly queries. This report should list the Query, # of executions, and Cost detail. It should exclude queries satisfied by cache because they have $0 cost. The report should also include identifying information about the query (project, user). The queries should show the most costly queries, based both on individual query cost as well as the frequency of query execution. Send this to engineers and data consumers on a regular basis so that they can stay abreast of the most costly queries and can work toward improvement.
Here is an example of such a report:
Consider Custom Cost Controls
BigQuery has project-level cost controls that can be applied to limit daily consumption by user or by project. This policy tracks consumption, and returns an error once the daily limit is exceeded. If this is appropriate for your use-case, see BigQuery Documentation6 for more detail.
Slot Reservation Strategy
When you are spending $1500/month or more on BigQuery Analysis, it might make sense to look at Slot Reservations. Without getting into detail on how slots work7, the main point to understand is that BigQuery supports a capacity-based pricing model where you may pay for a set amount of capacity for a flat fee. You are no longer are charged per-terabyte consumed by your queries. With this model, however, comes a fixed set of capacity that may have a performance impact on your queries.
Your Slot Reservation strategy may be complex. Your strategy will look different if your analysis costs are related to batch jobs, ad-hoc user exploration, or a combination of both. You may make hourly or 1-year commitments, each with increasing cost-benefit. With usage detail provided by Google Monitoring and the query audit detail, you can right-size your slot reservations.
Slot Recommender
Google is working on a (currently Alpha) Slot Recommender to help make slot reservations easier to use. Be on the lookout for its beta release, as it will simplify your research on determining the right level of slots to reserve.
Engage you Account Team
Put your Google Customer Engineer and the BigQuery product team to work. Arrange conversations with them and your engineers to talk about your use of BigQuery and to get ideas for improvement. You may learn about undisclosed alpha and roadmap features that may be helpful to you.
Data Engineer
A Data Engineer is someone who is creating BigQuery datasets, populating tables, authoring Views, and providing guidance to consumers (Either Humans or Services) on what is available and how to consume it.
Much can, and already has, been written for this role. We’ll provide a survey of the primary practices to consider to contain costs, however for someone new to BigQuery or needing to dig deeper in this role, general-purpose training material will be important to ensure you’re making effective use of BigQuery.
Partitioning and Clustering
Partitioning and Clustering your tables is all about arranging the data to avoid full-table scans. Full-table scans are costly because they require loading and processing the entire table column. This translates to poor performance and high query cost.
Partitioning
You can think of partitioning8 as similar to folders of a file system. The partition value is equivalent to a folder name. Specifying a column to partition on, your data will be placed in folders, and only those folders will be investigated if you use the proper query filter, or WHERE clause. Timestamps, for example, data ingestion timestamp, or integer values, are common to partition on.
–require_partition_filter option
The require_partition_filter flag9 can help prevent accidental full-table scans. It will decline any queries on a table that do not make use of a partition filter. It is a best practice to use this flag whenever your application supports it.
Queries will return the following if they do not include a partition filter:
Cannot query over table 'project_id.dataset.table' without a filter that can be used for partition elimination.
The --require_partition_filter can be used with the bq mk command when creating a table, and with the bq update command to update an existing table. For example:
bq update --require_partition_filter mydataset.mytable
Clustering
Clustering further reduces the data scanned by sorting storage of data by column values. Clustered columns help a “WHERE” clause narrow in on values that match, without scanning all rows of a table. Clustering can be done on one or multiple columns, but the ordering of the clustered values is important.
This10 excellent article by Felipe Hoffa, Google Developer Advocate, demonstrates the use and power of clustering your BigQuery data.
Flex Slot Reservations for Batch and ETL/ELT Jobs
Understanding how slot reservations work and considering Flex Slots11 can be helpful to contain costs particularly for large batch or ETL related jobs. Flex slots are slot-reservations that can last only minutes and can provide predictable and reduced query costs.
Materialized Views
Materialized Views12 provide cost-efficiency through periodic caching of query results. This is a global cache, and not user-specific like the default caching. It does consume extra Active Storage space. Materialized Views can benefit existing queries and tables without modification - the query optimizer will detect the materialized view upon query execution and use as appropriate. Google is continuing to enhance the functionality of Materialized Views to support more complex data structures.
Consider DataFlow or DataProc as an alternative
BigQuery helpfully distributes your query across a cluster of resources to return the results you need. You ask a question in the form of a SQL query, it provides the answer. If you have a job that is more complicated than asking a question, it might make sense to look at using Google’s DataFlow or DataProc to allow for more control and interaction on the data on a distributed basis. You can still use the BigQuery Storage API to access your existing datasets and read only relevant data.
Data Consumer
Data Consumers are those who are writing queries and pulling data from BigQuery. They have an important role in containing BigQuery costs and maintaining good performance by authoring good queries and interacting responsibly with the service. The following are important considerations for this group of users.
Be aware of query cost
Standard Pay-Per-Use rate is $5/TB.
BigQuery can, before executing, tell you how much data will be processed, so that you may understand the cost of your query. It’s a good idea to pay attention to the amount of data to be processed for any queries you compose and make sure it lines up with your expectation.
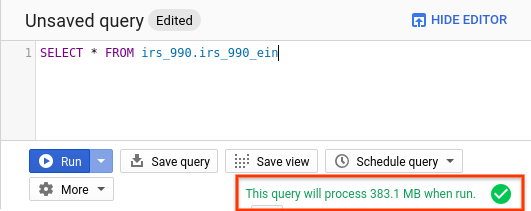
This query will cost USD $0.0018.
Read about more methods for estimating query costs13
Avoid SELECT * and use Preview
It is a best practice14 to only retrieve the columns you need. You can use the ‘Preview’ functionality of BigQuery to understand what the data looks like without incurring a query cost.
Make good use of Cache
BigQuery writes all query results to a table that acts as a cache. It is maintained per-user, per-project for 24 hours, with some exceptions. You are not charged for queries satisfied by this cache. Understanding how BigQuery’s cache works15 can be helpful to you in getting the most value from this functionality.
Use Partitions and Clusters
Partitions and Clusters help your query minimize the data it will process, which directly impacts cost and performance. Understanding how the data you are querying is partitioned and clustered is important in writing queries that execute efficiently.
Using Partitions
Querying a partitioned table16 effectively requires understanding how the table is partitioned. It may be partitioned on a hidden pseudo column such as _PARTITIONTIME.
Querying example:
|
|
You can determine if and how a table is partitioned by looking at its INFORMATION_SCHEMA:
|
|
This query will return the column name for the partitioned value.
Using Clusters
You can determine if and how a table is clustered by looking also looking at its INFORMATION_SCHEMA:
|
|
And then use the clustered columns in your query, ordering the “WHERE” clause based on their clustering_ordinal_position:
|
|
More detailed example of clustering is provided in the recommended article10.
Provide ongoing oversight of query quality
Your organization will probably have more BigQuery users than it will have BigQuery experts. It is likely that some users will not know or use efficient querying practices. With a regular review of high-cost queries, optimization opportunities can be identified. Review the High-Cost Query Report for queries to optimize. Make query optimization a routine part of your ongoing improvement and prioritization processes.
Designate experts, improve them, make sure people know how to find them
Your organization probably already has, or should develop, BigQuery experts who can provide leadership in helping others make their queries cost-effective. Make sure people know who these experts are and how they can work with them to improve their query quality.
Produce best practices
Build best practices for your organization so that anyone picking BigQuery can know how to do it efficiently. Build “paved roads” to make solving common problems easy and help encourage use of best practices.
Additional Resources
More best practices are covered in Google’s Controlling costs in BigQuery article and is recommended reading.
Summary
There are a lot of practices detailed in this article. There are a variety of use-cases for BigQuery, and not all of these practices may be useful for yours. Hopefully you can identify at least a few that will aid your ongoing process of managing BigQuery costs.
-
GCP Documentation - BigQuery - Introduction to Reservations ↩︎
-
BigQuery Documentation - Introduction to partitioned tables ↩︎
-
Introducing BigQuery Flex Sots for unparalleled flexibility and control ↩︎
-
BigQuery Documentation - Introduction to materialized views ↩︎
-
BigQuery Documentation - Estimating storage and query costs. ↩︎